-
личный кабинет
Войти в кабинет с помощью: 


Отслеживание здоровья физического сервера
Отслеживание здоровья физического сервера
Эта статья относится к серверам следующих типов:
- Сервера по услуге "Аренда физических серверов в дата-центре 1Gb.ru"
- Обратите внимание, эта статья ТОЛЬКО ПРО ЭТИ сервера, к VDS серверам HyperVPS и Linux KVM, и к серверам услуги "Цифровой ДЦ" это всё не относится.
Перед продажей все сервера проходят проверку, но при долгой аренде сервер может начать ломаться уже в процессе вашей работы с ним. У нас нет доступа на ваши физические сервера, и следить за их здоровьем мы не можем. Это должны делать вы.
Самое главное - следить за оставшимся ресурсом SSD дисков. Это критически важно, ресурс конечен, со временем он кончается у любых дисков, не важно их качество и тип. Важно вовремя заменить диск на новый. Мы сделаем это бесплатно и поможем скопировать данные на новый диск, если нужно.
Проверяйте здоровье ваших серверов примерно раз в несколько месяцев.
Отслеживание здоровья SSD и HDD
Если у вас Windows
Программа, которая лучше всего понимает самодиагностику всех дисков, это CrystalDiskInfo.
Скачайте программу CrystalDiskInfo с сайта https://crystalmark.info/en/software/crystaldiskinfo/ (лучше Standard Edition).
Поскольку сайт у них запутанный, можно скачать версию 9.7.2 от 08.2025 по прямой ссылке с нашего сайта.
Вот как выглядит нормальный SSD диск:
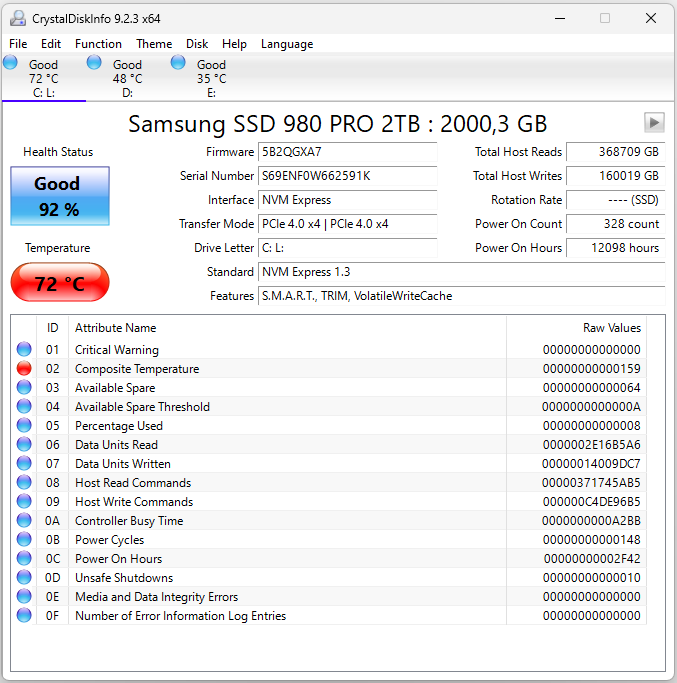
На температуру не смотрите - высокая температура полезна для флеш-памяти диска, и не вредит современным накопителям. Главное - оставшийся ресурс, в данном случае, это 92%. Надо беспокоиться тогда, когда ресурс приближается к нулю. Если ресурса осталось менее 10%, диск надо заменить. Обратитесь в поддержку, чтобы согласовать процедуру.
Вот как выглядит нормальный HDD диск:
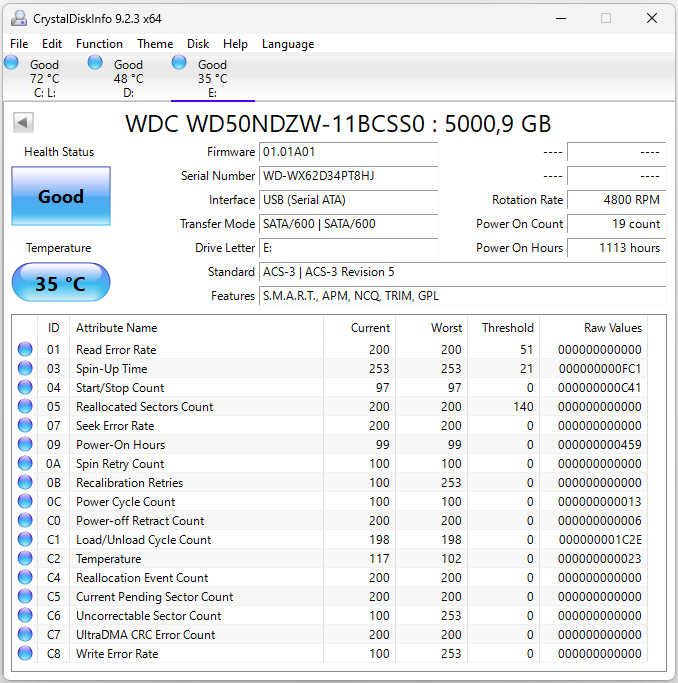
Ресурса там нет, но если нет красных показателей, то с диском всё хорошо.
Если у вас Linux
Вам нужна утилита smartctl. В Ubuntu например это пакет smartmontools, установить можно с помощью команды sudo apt install smartmontools.
Вот как выглядит проверка NVME SSD диска, команда -
sudo smartctl -a /dev/nvme0 | grep -iE '(model|test result|percentage|serial)'результат -
[root@nv97 ~]# sudo smartctl -a /dev/nvme0 | grep -iE '(model|test result|percentage|serial)'
Model Number: Samsung SSD 970 EVO Plus 250GB
Serial Number: S4EUNX0R906884T
SMART overall-health self-assessment test result: PASSED
Percentage Used: 3%Тут главное PASSED - общее здоровье в норме, и 3% - значит, использовано 3% ресурса. Если ресурса использовано больше 90%, диск надо заменить. Обратитесь в поддержку, чтобы согласовать процедуру.
Проверьте все диски - nvme0, nvme1, nvme2, nvme3, и так далее, по числу NVME дисков вашего сервера.
Вот как выглядит проверка SATA SSD или HDD диска, команда -
sudo smartctl -a /dev/sda | grep -iE '(model|test result|serial)'результат -
[root@nv65 ~][root@nv65 ~]# sudo smartctl -a /dev/sda | grep -iE '(model|test result|serial)'
Model Family: Intel 53x and Pro 1500/2500 Series SSDs
Device Model: INTEL SSDSC2BW480A4
Serial Number: CVDA4466065J4805GN
SMART overall-health self-assessment test result: PASSEDroot@nv-133225:/home/ubuntu# sudo smartctl -a /dev/sda | grep -iE '(model|test result|serial)'
Model Family: HGST Travelstar 7K1000
Device Model: HGST HTS721010A9E630
Serial Number: JR1000BNJBBZ2E
SMART overall-health self-assessment test result: PASSEDТут главное PASSED - общее здоровье в норме.
Проверьте все диски - sda, sdb, sdc, sdd, и так далее, по числу SATA дисков вашего сервера.
Если у вас smartctl какой-то другой версии, то та часть, которая grep, может не сработать, тогда уберите её (просто sudo smartctl -a /dev/sda), и читайте вывод полностью, по аналогии.
Проверка работы системы охлаждения
С проверкой системы охлаждения всё немного сложнее, поскольку многие десктопные процессоры и сервера в целом рассчитаны на работу в режиме предельного нагрева (Thermal Throttle). Например, для серверов 7300U / 8650U, или на современном Ryzen 9700X, работа на максимальной возможной температуре является нормальным оптимальным режимом работы, предусмотренным производителем. Иногда охладить кристалл процессора ниже этой температуры в реальных условиях попросту невозможно.
Исходя из этого, трудно придумать какой-то единый для всех серверов показатель, который можно проверить и сразу понять, всё ли работает нормально.
Однако общее правило всё же есть: если система охлаждения сервера неисправна, будут наблюдаться сильные нетипичные тормоза, а также, иногда, самостоятельные выключения сервера. Если такое есть, обратитесь в поддержку для более точного анализа проблемы, на основе особенностей конкретного сервера специалисты подскажут, куда смотреть.
Если такого не наблюдается, если работа сервера в норме, то можно продолжать работать, скорее всего, всё нормально.